

Updates: We now release pretrained GPT4Tools models with Vicuna-13B and released the dataset for self-instruction!
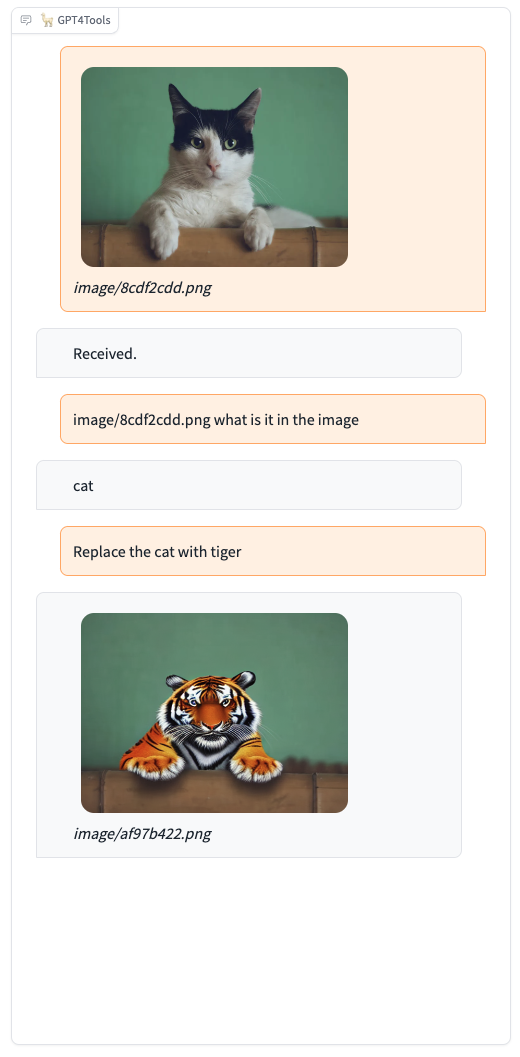
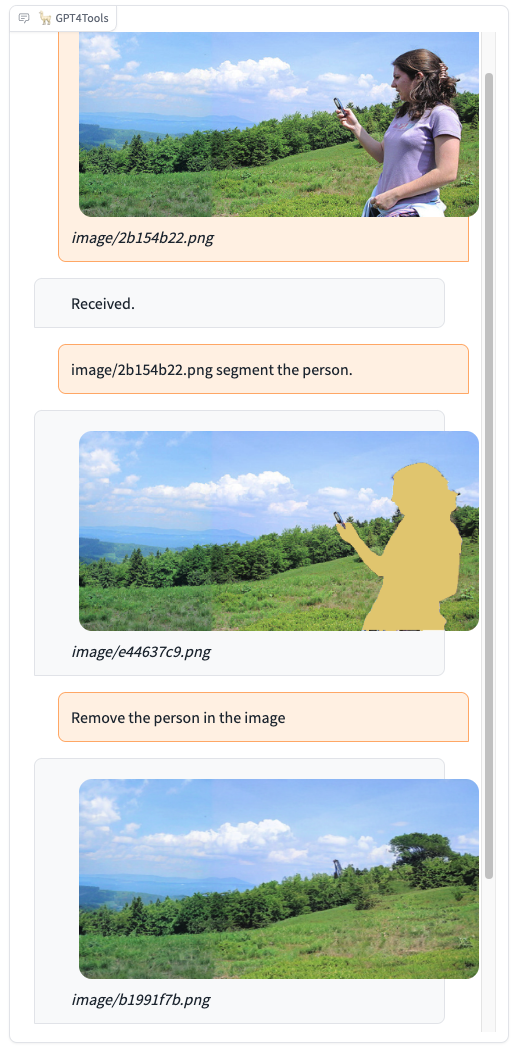
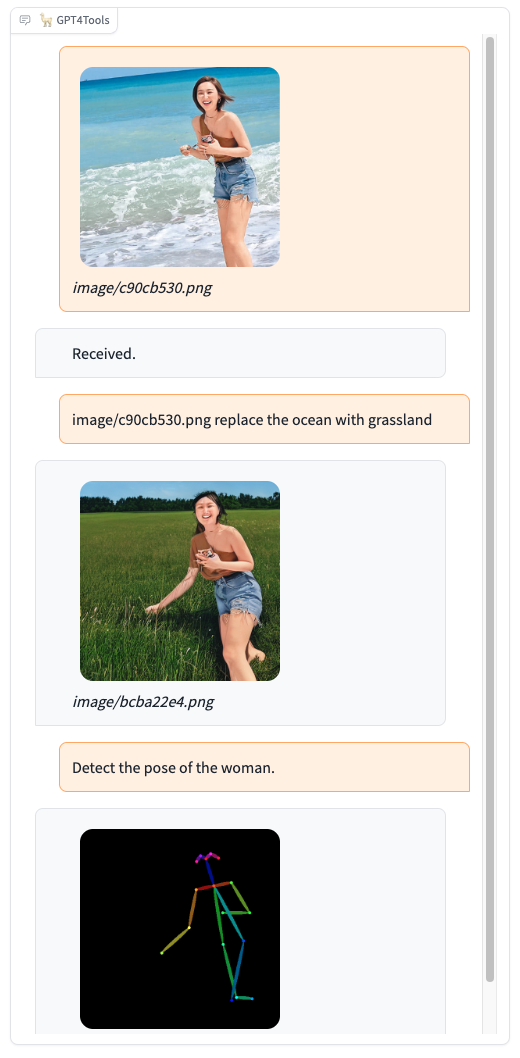
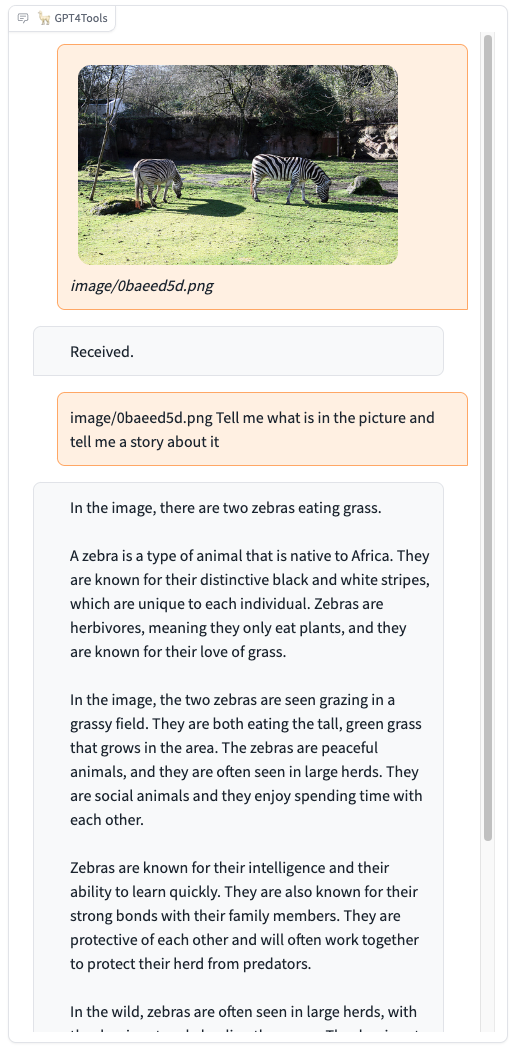
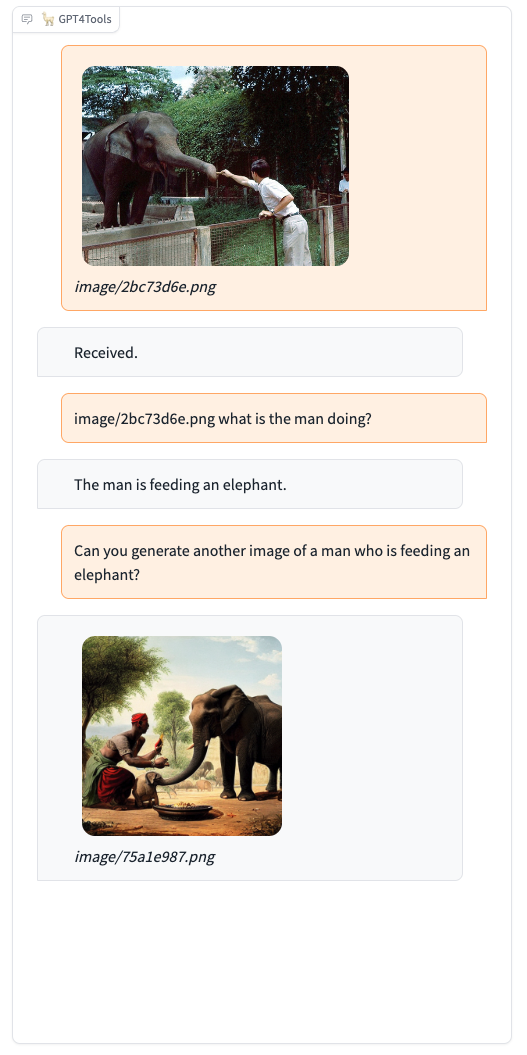
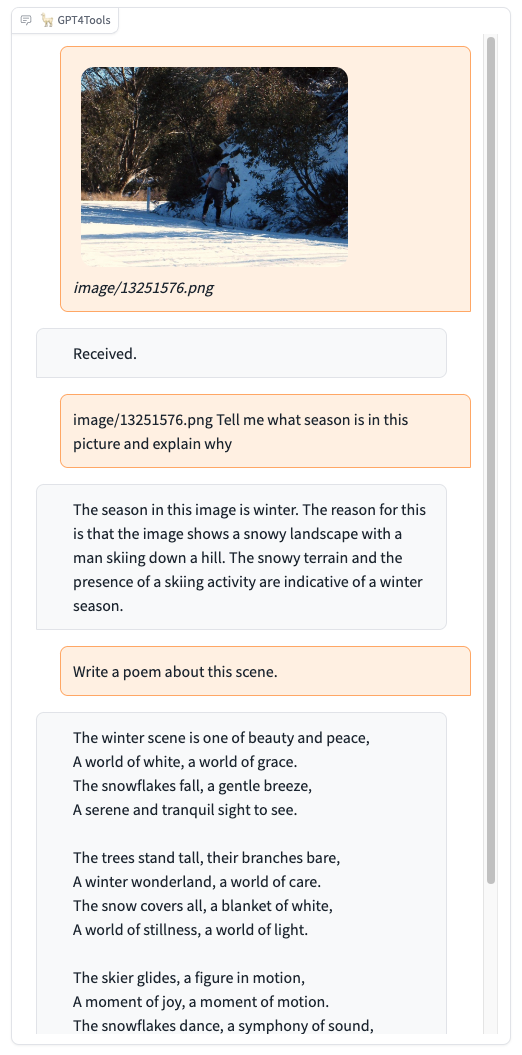
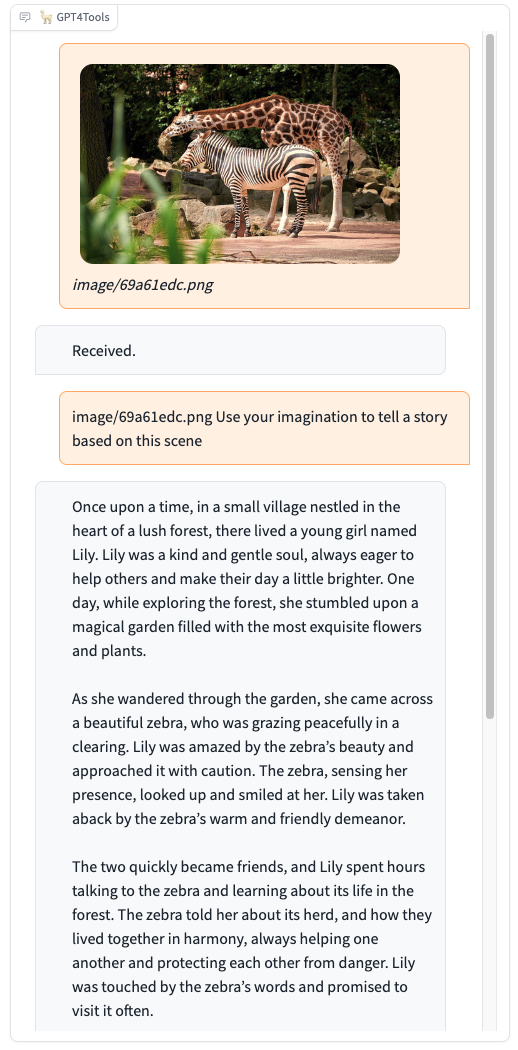
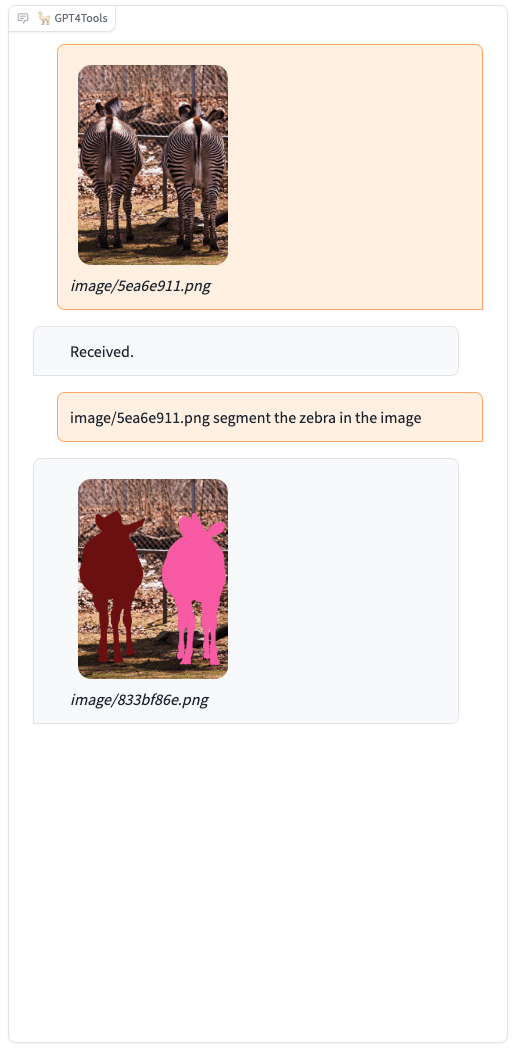
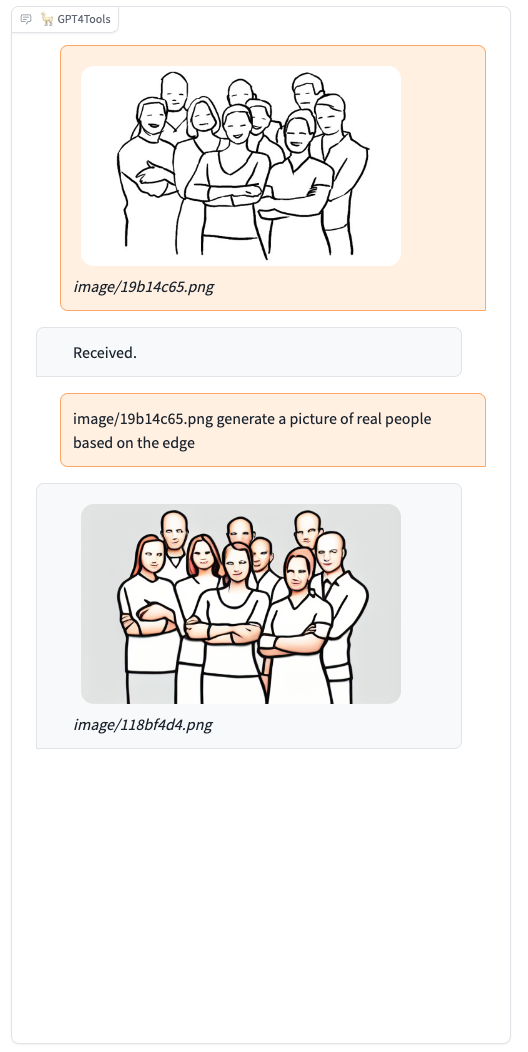
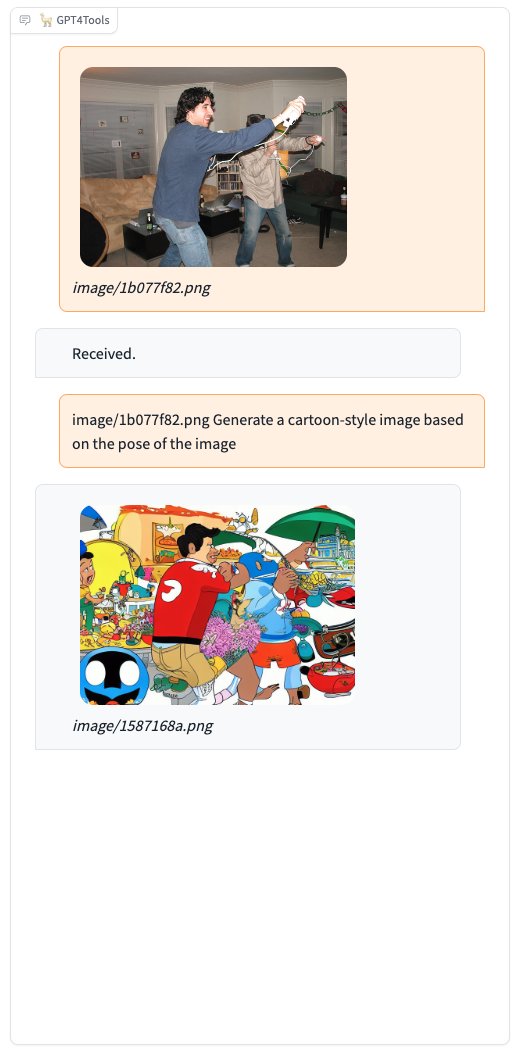
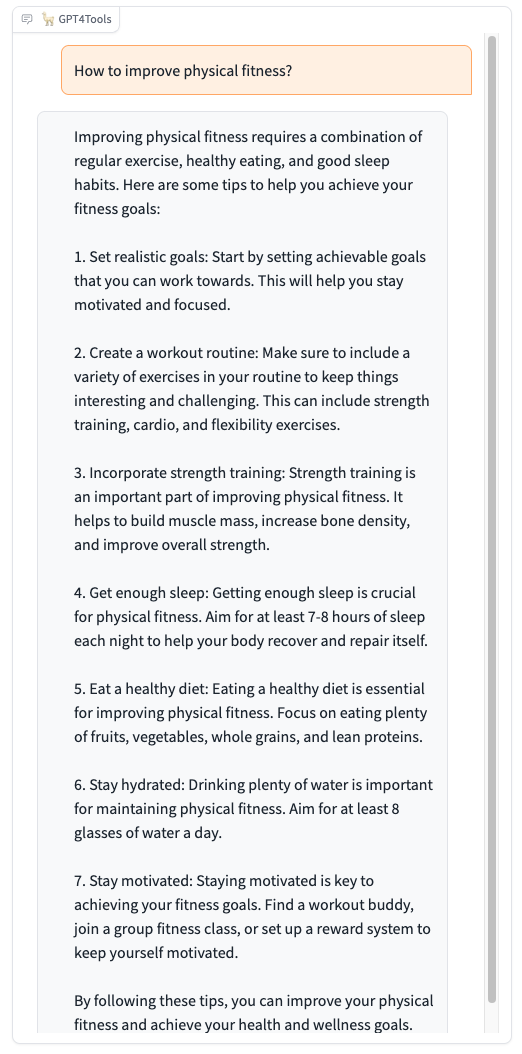
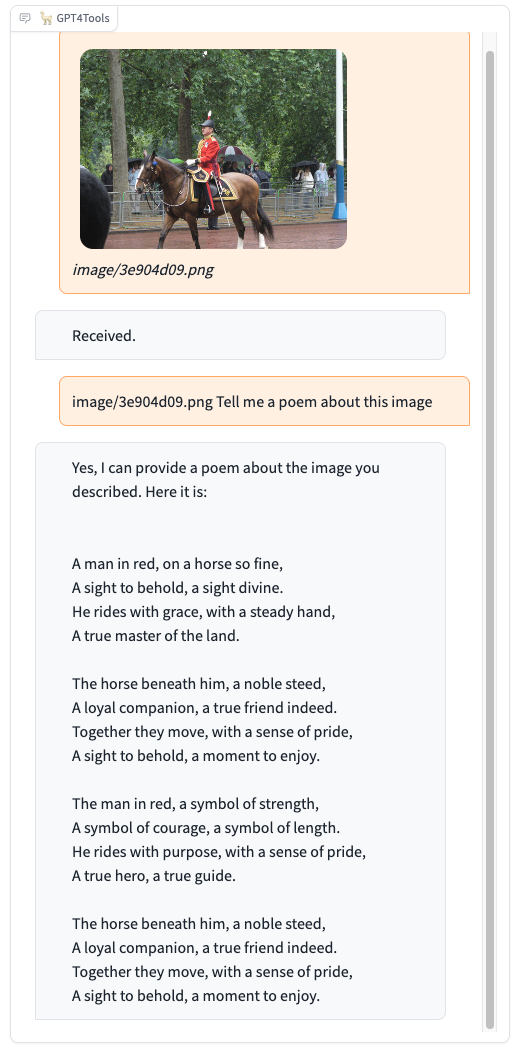
Please try our demo here, you can upload an image and chat in the box. When you want to interact with images, it is recommended to add the image path before the instruction, such as "image/695a805c.png replace the cat with a dog."
GPT4Tools is a centralized system that can control multiple visual foundation models. It is based on LLaMA, and 71K self-built instruction data. By analyzing the language content, GPT4Tools is capable of automatically deciding, controlling, and utilizing different visual foundation models, allowing the user to interact with images during a conversation. With this approach, GPT4Tools provides a seamless and efficient solution to fulfill various image-related requirements in a conversation. Different from previous work, we support users teach their own LLM to use tools with simple refinement via self-instruction and LoRA.
GTP4Tools mainly contains three parts: LLM for instruction, LoRA for adaptation, and Visual Agent for provided functions. It is a flexible and extensible system that can be easily extended to support more tools and functions. For example, users can replace the existing LLM or tools with their own models, or add new tools to the system. The only things needed are finetuned the LoRA with the provided instruction, which teaches LLM to use the provided tools.
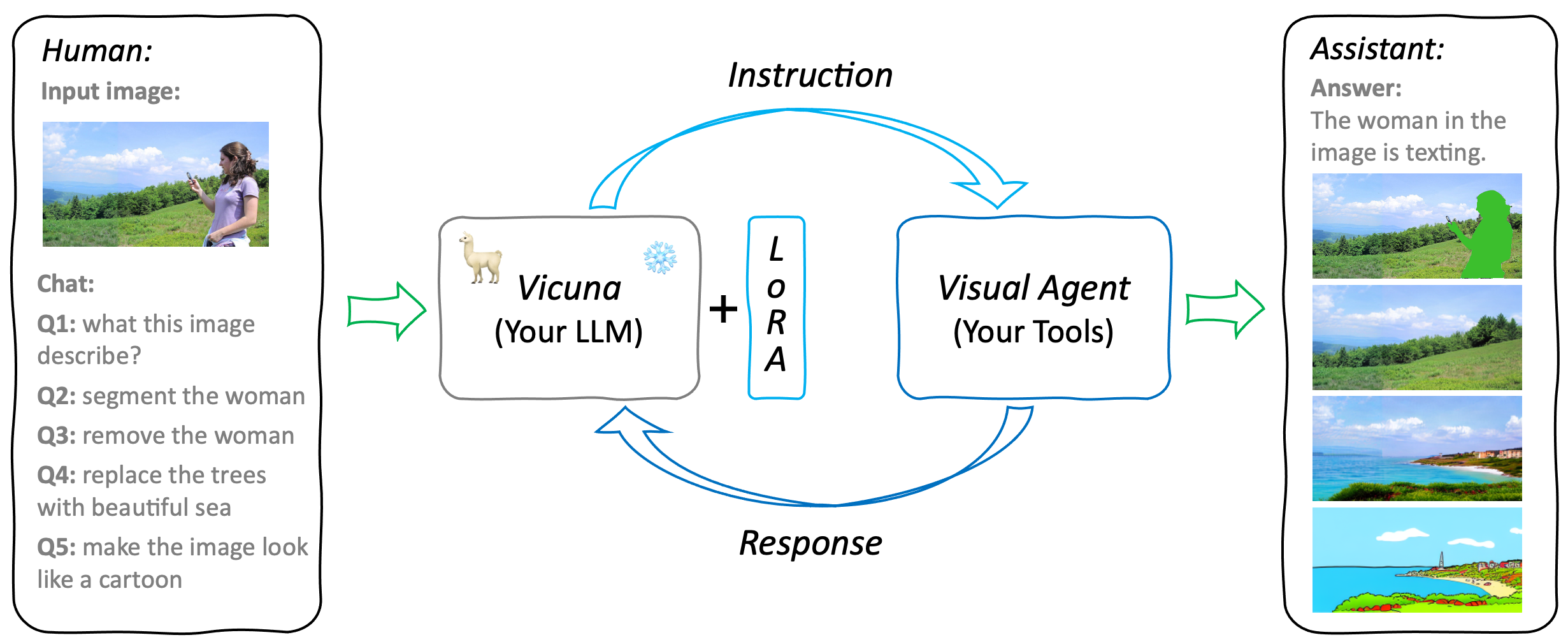
Human-assistant interaction workflow in GPT4Tools.
We use the collected data that contains 71K instruction-following info for fine-tuning the GPT4Tools model. In particular, we fed GPT-3.5 with captions from 3K images and descriptions of 22 visual tasks. This produced 66K instructions, each corresponding to a specific visual task and a visual foundation model (tool). Subsequently, we eliminated duplicate instructions and retained 41K sound instructions. To teach the model to utilize tools in a predefined manner, we followed the format used in VisualChatGPT and converted these instructions into a conversational format.
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.